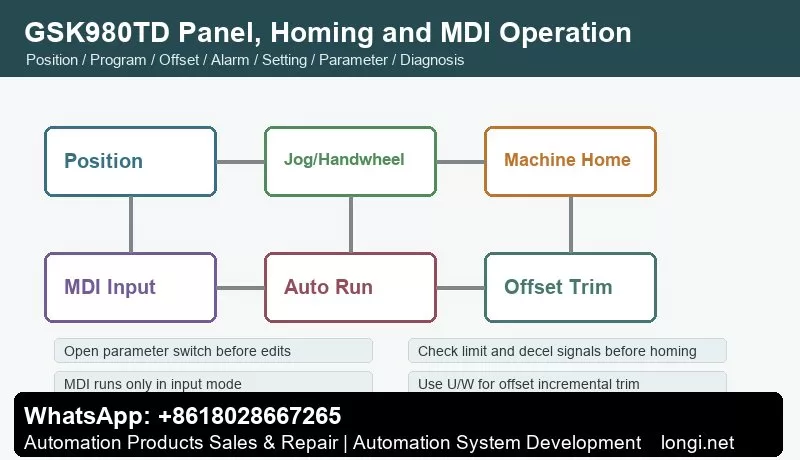
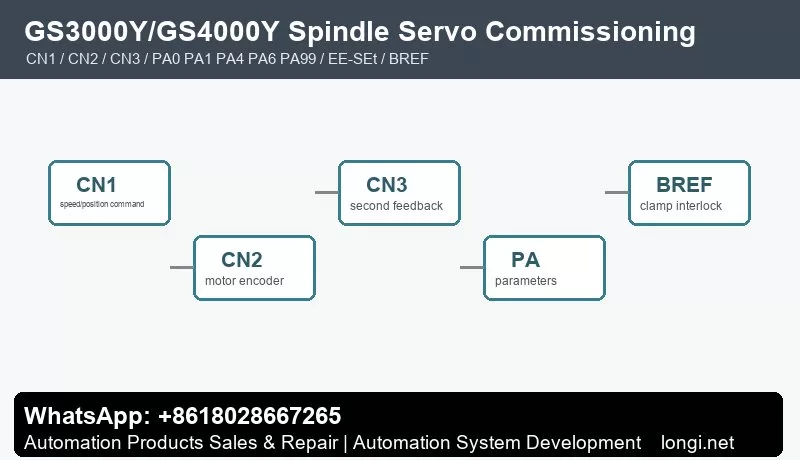
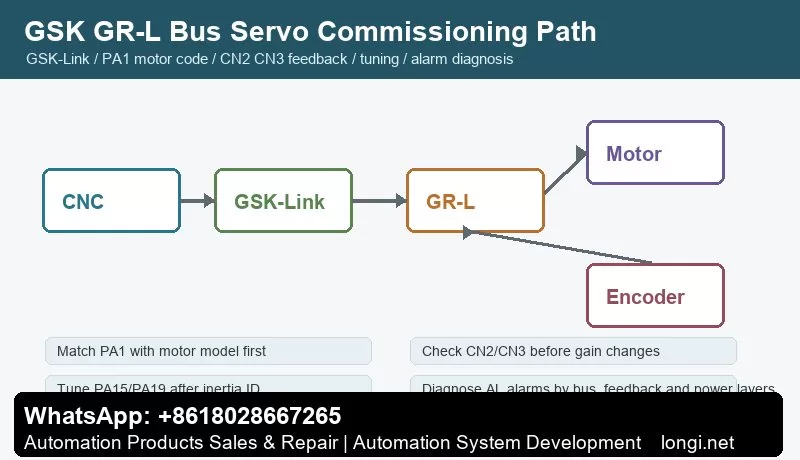
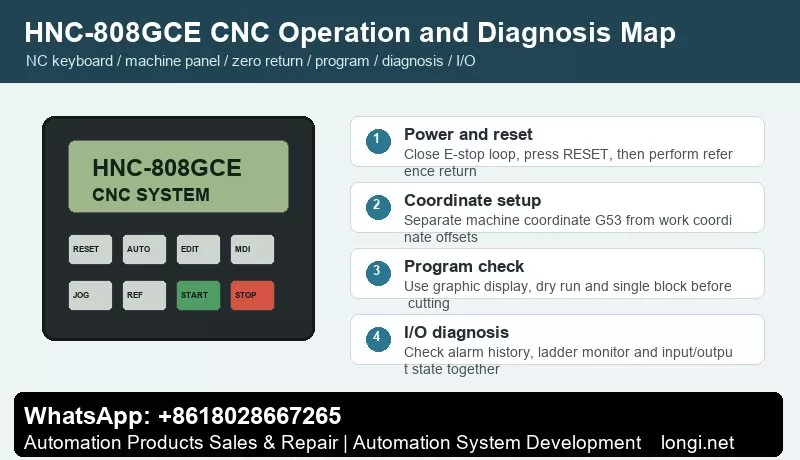
GSK DA98A/DA98D AC Servo Drive Manual Guide: Replacement Matching, Panel JOG, Parameter Save, Electronic Gear, Encoder and Alarm Repair DA98A/DA98D Maintenance Focus GSK DA98A and DA98D are later members of the DA98 AC servo drive family. They are used on CNC lathes, milling machines, grinders, feed axes and automatic positioning mechanisms. They share the same service logic as DA98, but…