1. Overview of the Fault
In particle size analysis systems, the instrument hardware, operating software, communication drivers, database components, and Windows environment work together as one complete measurement platform. When a user reports that the software cannot start, it is easy to assume that the analyzer itself is faulty. However, software startup failure and instrument hardware failure are two different categories of problems and should be diagnosed separately.
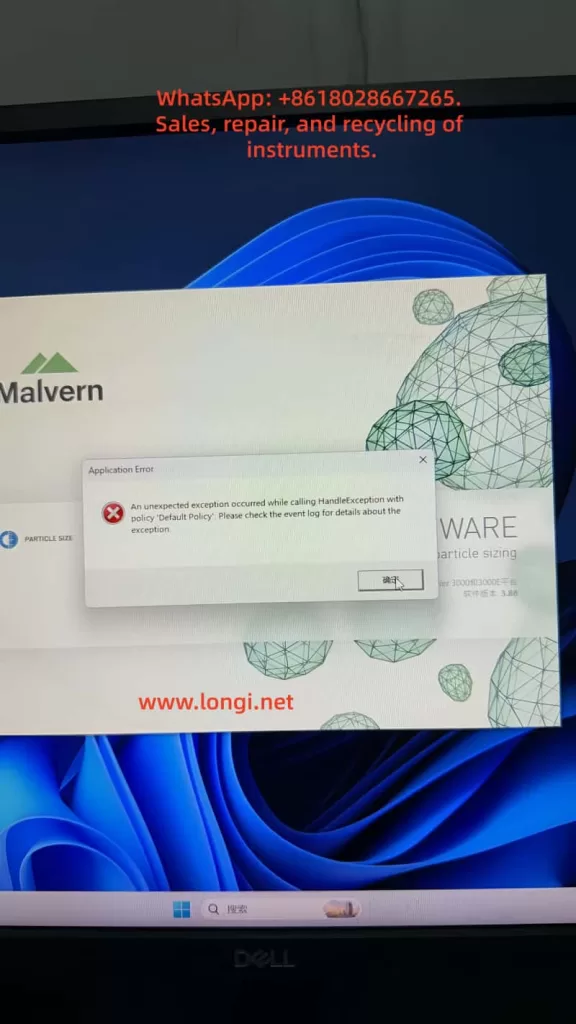
A typical fault can occur on a Malvern Mastersizer 3000 system where the software starts, displays the Malvern splash screen, and then immediately shows an Application Error message:
An unexpected exception occurred while calling HandleException with policy ‘Default Policy’. Please check the event log for details about the exception.
At this stage, the software has not entered the main operating interface. The user cannot connect to the instrument, load measurement methods, perform background measurements, run samples, or analyze data. In the Windows Event Viewer, the user may find entries such as Application Error, Windows Error Reporting, Application Hang, .NET Runtime errors, or records mentioning KERNELBASE.dll.
The key point is that this type of error should not be immediately interpreted as a laser particle size analyzer hardware failure. It is more likely to be a Windows-side software environment problem, especially when the error appears before the main Mastersizer interface opens.
For a Malvern Mastersizer 3000 system, startup failure is usually related to one or more of the following:
Windows compatibility issue
Damaged software installation
Missing or corrupted .NET Framework components
Missing or corrupted Microsoft Visual C++ runtime libraries
Damaged user configuration files
Damaged local database or method database
Malvern background service failure
Device driver conflict
Permission issue
Windows update conflict
Security software interference
Only after the software can open normally and enter the instrument connection stage should the instrument body, laser source, optical bench, dispersion unit, communication interface, and hardware modules be considered as the primary fault targets.

2. Why This Fault Should Not Be Judged as Instrument Hardware Damage First
A Malvern Mastersizer 3000 system consists of several layers. The analyzer hardware is only one part of the system. The software layer must start correctly before any meaningful judgment can be made about the instrument body.
If the instrument hardware were the direct cause, the software would usually open first and then show instrument-related errors, such as:
Instrument not found
Communication failure
Laser status abnormal
Optical alignment failure
Background signal abnormal
Wet dispersion unit not detected
Dry dispersion unit not detected
SOP cannot initialize the accessory
Obscuration cannot be stabilized
Measurement signal unstable
In contrast, when the software crashes during the splash screen stage, before entering the main interface, the problem is normally located in the PC-side software environment. At this moment, the software may not even have started instrument communication. It may still be loading its program framework, local database, services, configuration files, user profile, report templates, runtime libraries, or graphical components.
Therefore, if the software fails before reaching the main interface, the correct diagnostic direction is:
First diagnose the computer, operating system, software installation, runtime components, database, configuration files, and services. Do not disassemble the particle size analyzer body at this stage.
A simple but important test is to disconnect the instrument from the computer and then open the software alone. If the software still reports the same Application Error without any instrument connected, the fault is almost certainly not caused by the analyzer hardware.
3. Meaning of the Application Error Message
Windows Application Error is a general crash event. It does not represent one specific Malvern fault code. It only means that a program encountered an unhandled exception and Windows recorded the crash.
The most important fields in Windows Event Viewer are:
Faulting application name
Faulting module name
Exception code
Fault offset
Process ID
Application path
Module path
Time of event
Among these fields, the most important one is the faulting application name.
If the faulting application name is Mastersizer.exe, Malvern.exe, MalvernPanalytical-related executable, or another executable clearly belonging to the Mastersizer software, the log is useful for diagnosing the Mastersizer software failure.
If the faulting application name is mmc.exe, then the crashed program is not Mastersizer. mmc.exe is Microsoft Management Console. Windows Event Viewer, Device Manager, Services, and many Windows administrative tools run under mmc.exe.
For example, if the Event Viewer shows:
Faulting application name: mmc.exe
Faulting module name: KERNELBASE.dll
Application path: C:\Windows\System32\mmc.exe
This means the Windows management console itself crashed. It does not prove that the Mastersizer 3000 software crashed in KERNELBASE.dll. It also does not tell us which Mastersizer component failed.
This distinction is very important. A wrong interpretation of the Event Viewer log can lead to a completely wrong repair direction.
4. Understanding KERNELBASE.dll in the Event Log
KERNELBASE.dll is a core Windows system component. Many application exceptions are eventually reported through KERNELBASE.dll. Therefore, seeing KERNELBASE.dll in the faulting module field does not automatically mean that KERNELBASE.dll itself is damaged.
KERNELBASE.dll often appears when an application throws an exception that is not properly handled. The real cause may be:
.NET runtime exception
Application configuration error
Database access failure
Missing software dependency
Permission problem
Program module conflict
Windows compatibility problem
Access violation
Damaged user profile
Security software blocking the program
Corrupted application file
If the exception code is 0xe0434352, it often indicates a .NET-related exception. If the exception code is 0xc0000005, it often indicates an access violation, which may be caused by a damaged module, incompatible driver, memory access issue, or software conflict.
However, the KERNELBASE.dll record is only meaningful if the faulting application is the Mastersizer software. If the faulting application is mmc.exe, that record belongs to Windows Event Viewer or another Windows console tool, not to the Malvern application.
5. Windows 11 Compatibility Risk with Older Instrument Software
Many laboratory instruments are designed and validated for specific Windows versions. An instrument software package may install successfully on a newer Windows system, but that does not mean it is fully compatible or stable.
In many real service cases, older scientific instrument software may work reliably on Windows 10 but fail on Windows 11, especially after major Windows updates. Mastersizer 3000 software version 3.88, for example, may encounter compatibility risks on a newer Windows 11 environment, depending on the exact software release, driver package, service components, and instrument configuration.
Possible symptoms include:
Software installs but cannot start
Software starts but crashes at the splash screen
Local database cannot initialize
Malvern service fails to start
USB or Ethernet instrument driver does not load correctly
Software cannot register required components
Report or graph module fails to initialize
.NET component throws an exception
User configuration cannot be read
Windows security settings block background services
For normal office applications, Windows 11 may be suitable. For laboratory instrument software, however, stability and validated compatibility are more important than using the newest operating system.
If the problem appeared after replacing the computer, reinstalling the operating system, or upgrading to Windows 11, system compatibility should be treated as a high-priority suspect.
A practical service recommendation is to test the same Mastersizer software version on a clean Windows 10 64-bit computer. If the software opens normally on Windows 10 but not on Windows 11, the problem is very likely related to operating system compatibility or software environment differences.
6. What the Mastersizer 3000 Software Loads During Startup
When the Mastersizer 3000 software starts, it does much more than display a user interface. During startup, it may load and initialize:
Main application framework
User profile
Instrument configuration
Local database
Measurement records
SOP methods
Report templates
Analysis calculation modules
Graphical display components
Malvern background services
Communication services
USB or Ethernet drivers
License or authorization components
Cloud or update services
Windows user permissions
Temporary folders and cache files
If any of these components are missing, damaged, blocked, or incompatible, the software may crash before reaching the main interface.
For example, if the user configuration file is damaged, the software may fail while loading the last used instrument, window layout, default method, or user preference settings. If the local database is damaged, the software may fail while reading historical measurement data or method libraries. If a background service is not running, the main program may fail when trying to communicate with that service.
Therefore, the startup phase should be treated as a software environment initialization process, not as an instrument measurement process.
7. Recommended Diagnostic Procedure
A structured diagnostic sequence is essential. The goal is to separate software failure from hardware failure, then identify the exact software layer causing the crash.
Step 1: Disconnect the Instrument and Start the Software Alone
Disconnect the Mastersizer 3000 instrument body from the computer. Also disconnect wet dispersion units, dry dispersion units, USB cables, Ethernet cables, and any external accessories if possible.
Then start the Mastersizer software alone.
If the software opens normally without the instrument connected, the software itself may be functional, and the problem may be related to instrument communication, device driver initialization, or a connected accessory.
If the software still reports the same Application Error, the fault is most likely in the computer, software installation, database, configuration files, Windows environment, or runtime components.
This is the first and most important separation test.
Step 2: Run the Software as Administrator
Right-click the Mastersizer 3000 shortcut and choose Run as administrator.
If the software opens correctly as administrator, the fault may be caused by insufficient user permissions, blocked access to the database folder, blocked configuration directory, or restricted service communication.
If the software still reports the same error, the problem is not simply caused by normal user permissions.
Step 3: Find the Correct Event Viewer Log
Open Windows Event Viewer:
Windows Logs → Application
Run the Mastersizer software again and allow it to fail. Record the exact time of the error. Then check the Application log around that time.
Look for entries from:
Application Error
Windows Error Reporting
.NET Runtime
Application Hang
MalvernPanalytical
Malvern
Mastersizer
Open each related record and confirm the faulting application name.
A valid record should show a faulting application related to Mastersizer or Malvern. If the application name is mmc.exe, the user has selected the wrong record. That record belongs to Windows Event Viewer or another Windows management console.
The following fields should be recorded:
Faulting application name
Faulting module name
Exception code
Application path
Module path
Fault offset
Only after these details are available can the next diagnostic step be accurate.
Step 4: Check Malvern Services
Press Win + R, type:
services.msc
Then check whether Malvern or MalvernPanalytical services are present and running. Depending on the software version, there may be services related to cloud communication, data, instrument communication, update functions, or background control.
If a Malvern service is stopped, try to start it manually. If it fails to start, record the error message. A service that cannot start may indicate:
Damaged installation
Missing dependency
Permission issue
Database problem
Windows service registration failure
Security software blocking the service
The Mastersizer front-end software may rely on these background services. If service communication fails, the main software may crash during startup.
Step 5: Confirm the Windows Version
Confirm the operating system details:
Windows 10 or Windows 11
64-bit or 32-bit
Exact Windows build version
Whether Windows was recently updated
Whether the computer was recently replaced
Whether the software was installed on a newly prepared system
If the system is Windows 11 and the Mastersizer software version is older, compatibility must be considered. Testing on Windows 10 64-bit is often the fastest way to confirm whether the operating system is part of the problem.
Step 6: Check Recent Installation or Repair Activity
If the Event Viewer shows many MsiInstaller records, it may indicate that Windows Installer recently installed, repaired, reconfigured, or checked software components.
Ask the user:
Was the software recently installed?
Was the operating system reinstalled?
Was the software copied from another computer instead of installed properly?
Was a software repair attempted?
Were Malvern components removed?
Was a cleaner tool used?
Was antivirus software recently installed?
Was Windows recently updated?
Were ProgramData or AppData folders deleted?
A failed or incomplete installation is a common cause of startup errors.
Step 7: Back Up Data Before Repairing or Reinstalling
Before repairing or reinstalling the software, back up all important user data. This may include:
Measurement records
SOP methods
Report templates
Instrument configuration
User settings
Databases
Calibration-related records
Do not simply delete Malvern folders. Some folders may contain important laboratory data.
Possible data locations include:
C:\ProgramData\Malvern Instruments
C:\ProgramData\Malvern Panalytical
C:\Users\Public\Documents\Malvern Instruments
C:\Users[User]\AppData\Roaming\Malvern
C:\Users[User]\AppData\Local\Malvern
The exact location depends on software version and installation configuration, but the principle is the same: back up before removing or reinstalling.
8. Database or Configuration File Damage
Damaged configuration files or local databases are common in laboratory software. They may be caused by:
Unexpected power failure
Forced shutdown during software operation
Software crash during measurement
Disk space shortage
Antivirus quarantine
Windows update changing permissions
Damaged Windows user profile
File system error
Improper software migration
Manual deletion of folders
Typical symptoms include:
Software crashes before the main interface opens
Software cannot load methods
Historical records cannot be opened
Report templates disappear
Only one Windows user account fails
New Windows user account works
Software crashes when loading the last used configuration
A useful test is to create a new Windows administrator account and run the Mastersizer software from that account. If the software opens under a new user but not under the original user, the original user profile or user-level configuration is likely damaged.
If the software fails under all Windows users, the problem is more likely in the common software installation, database, runtime components, Windows services, or operating system compatibility.
9. .NET Framework and Visual C++ Runtime Issues
Many scientific instrument programs depend on Microsoft .NET Framework and Microsoft Visual C++ Redistributable packages. If these components are missing or damaged, the software may report Application Error, .NET Runtime error, KERNELBASE.dll exception, or crash during startup.
Important points:
Installing only the latest runtime may not be enough. Older software may require a specific Visual C++ runtime version.
Both x86 and x64 runtime packages may be required, even on a 64-bit Windows system.
.NET Framework 4.x components should be checked and repaired if the log points to .NET Runtime.
If the Event Viewer shows .NET Runtime, clr.dll, or exception code 0xe0434352, the issue should be treated as a .NET application exception.
In such cases, repair actions may include:
Repairing .NET Framework
Enabling required Windows .NET features
Repairing Visual C++ Redistributables
Reinstalling the Malvern software
Running the installer as administrator
Checking whether antivirus software blocked registration of DLL files
10. Instrument Communication and Driver Problems
Even though startup failure is usually a PC-side issue, communication and driver problems should not be ignored completely. Some instrument software automatically scans connected hardware during startup. If a device driver or external accessory responds abnormally, the software may crash.
This is why the disconnected-instrument test is necessary.
If the software opens when the instrument is disconnected but crashes when the instrument is connected, check:
Instrument power supply
USB or Ethernet cable
USB port stability
Device Manager recognition
Malvern instrument driver installation
IP address or network configuration
Firewall settings
Wet dispersion unit connection
Dry dispersion unit connection
Accessory communication
Malvern service status
For laboratory instruments, avoid unstable USB hubs, long USB extension cables, front-panel USB ports, and docking stations whenever possible. Direct rear-panel USB or a stable Ethernet connection is preferred.
11. How to Explain the Problem to the Customer
A professional explanation to the customer should avoid premature conclusions. The recommended wording is:
Based on the current symptom, the Mastersizer 3000 software crashes during startup before entering the main operating interface. This suggests a PC-side software or Windows environment issue rather than direct damage to the particle size analyzer hardware. The next step is to disconnect the instrument and open the software alone, then check the correct Windows Event Viewer record. The useful record must show Mastersizer or Malvern as the faulting application. If the log shows mmc.exe, it is the Windows Event Viewer itself and not the Mastersizer software. After the correct log is confirmed, we can determine whether the fault is related to .NET, KERNELBASE.dll, Malvern software modules, database files, configuration files, services, drivers, or Windows compatibility.
This explanation is clear and technically accurate. It also prevents the customer from unnecessarily disassembling the instrument or sending the analyzer body for repair before software-side diagnosis is complete.
12. Practical Service Strategy for Repair Companies
For a repair company or third-party service provider, this type of fault should be handled in three levels.
Level 1: Remote Diagnosis
Collect:
Photos of the error message
Video of the startup process
Software version
Windows version
Instrument connection status
Event Viewer details
Malvern service status
Recent installation or update history
The goal is to confirm whether the problem is software-side or hardware-side.
Level 2: PC-Side Software Repair
If the fault is confirmed as a PC-side software problem, the repair work may include:
Backing up data
Repairing runtime libraries
Repairing .NET Framework
Checking Windows services
Checking Malvern services
Reinstalling the Mastersizer software
Reinstalling drivers
Creating a new Windows user
Checking compatibility mode
Testing on Windows 10 64-bit
Level 3: Full Instrument Commissioning
Only after the software opens normally should the instrument be connected for complete testing.
Commissioning should include:
Instrument recognition
Communication stability
Laser status
Background signal
Optical alignment
Wet or dry dispersion unit recognition
Standard sample repeatability
SOP loading
Data saving and report generation
This sequence avoids unnecessary hardware repair and protects customer data.
13. Folders That Should Not Be Deleted Carelessly
Customers sometimes try to solve software problems by deleting folders. This is risky because laboratory software may store important data in hidden or system folders.
Avoid deleting Malvern-related folders before backup. They may contain:
Measurement history
SOP methods
User configuration
Report templates
Instrument configuration
Database files
Calibration-related files
Cache files
Important locations may include:
C:\ProgramData\Malvern Instruments
C:\ProgramData\Malvern Panalytical
C:\Users\Public\Documents\Malvern Instruments
C:\Users[User]\AppData\Roaming\Malvern
C:\Users[User]\AppData\Local\Malvern
Before reinstalling software, always back up these folders or use the manufacturer-recommended backup method.
14. Case-Based Preliminary Conclusion
Based on the described case, the following conclusions can be made:
The Mastersizer 3000 software displays an Application Error during startup.
The software crashes before entering the main operating interface.
Running as administrator does not solve the issue.
The Event Viewer contains Application Error and Windows Error Reporting records.
One opened Application Error 1000 record shows faulting application name mmc.exe, which means it is a Windows Event Viewer or Microsoft Management Console crash, not the Mastersizer software crash.
The computer appears to be running a newer Windows 11 environment.
Mastersizer 3000 software version 3.88 may have compatibility risks on newer Windows 11 systems.
There is currently no evidence proving damage to the analyzer hardware, laser unit, optical bench, or dispersion unit.
The next step is to generate the Mastersizer error again and locate the correct Event Viewer record where the faulting application is Mastersizer or Malvern.
If the software still crashes with the instrument disconnected, the fault should be handled as a PC-side software environment issue.
If the software opens when the instrument is disconnected but crashes when the instrument is connected, then instrument communication, drivers, or accessory hardware should be checked.
The most reasonable current repair direction is:
Repair or verify the PC-side software environment first, then perform instrument communication and hardware commissioning. Do not disassemble the analyzer body before confirming that the software can start correctly.
15. Recommended Final Troubleshooting Workflow
The following workflow is recommended for field service:
Disconnect the Mastersizer instrument and all accessories from the computer.
Start the Mastersizer software alone.
If the error appears again, record the exact time.
Open Windows Event Viewer.
Go to Windows Logs → Application.
Find records around the exact error time.
Open Application Error, Windows Error Reporting, and .NET Runtime records.
Confirm whether the faulting application is Mastersizer or Malvern.
Ignore records where the faulting application is mmc.exe unless troubleshooting Windows itself.
Record the faulting module and exception code.
Check Malvern services in services.msc.
Create a new Windows administrator account and test again.
Confirm whether the computer is Windows 10 or Windows 11.
If using Windows 11, test the same software on Windows 10 64-bit.
Back up measurement data, SOP methods, reports, and configuration files.
Repair or reinstall the Mastersizer software and required runtime components.
Restart the computer.
Start the software without the instrument connected.
If the software opens normally, reconnect the instrument.
Test communication, laser status, background signal, dispersion unit recognition, and standard sample repeatability.
This workflow is practical, safe, and technically logical. It reduces misdiagnosis and avoids unnecessary hardware repair.
16. Conclusion
A Malvern Mastersizer 3000 Application Error during software startup should be treated as a software-side startup failure until proven otherwise. When the error occurs before the main interface opens, the most likely causes are Windows compatibility, damaged software components, missing runtime libraries, corrupted configuration files, database problems, Malvern service failure, or driver conflicts.
The Windows Event Viewer is useful, but only if the correct record is selected. If the faulting application is mmc.exe, the crash belongs to Microsoft Management Console, not to the Mastersizer software. The useful log must show Mastersizer or Malvern as the faulting application. The faulting module, exception code, and application path should then be used to determine the next repair step.
For this type of fault, the correct principle is:
Software before hardware.
Logs before disassembly.
Backup before reinstallation.
Offline startup before instrument connection.
Windows compatibility before component-level repair.
Following this approach protects customer data, avoids unnecessary instrument disassembly, and greatly improves the accuracy of the diagnosis.