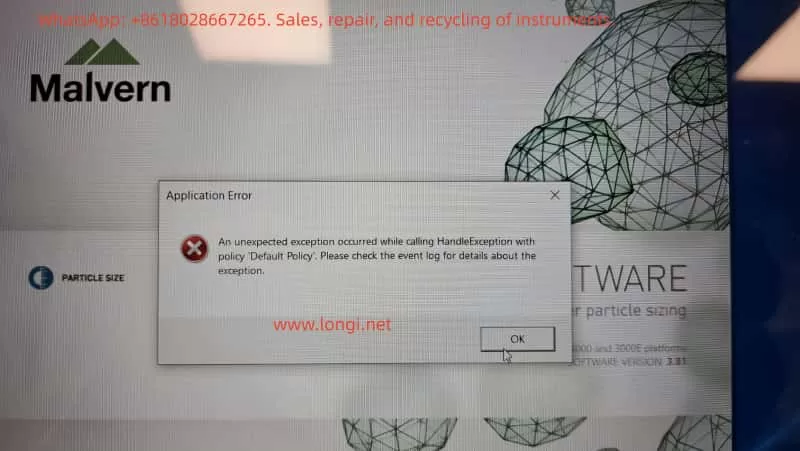
Abstract
In industrial automation motion control systems, the meanings of servo drive fault codes are diverse. In a recent on-site case, the SEW MOVIDRIVE® Generation C series drive exhibited fault code 10.10 after replacing a SICK encoder. This fault is often misdiagnosed as an encoder not being zero-calibrated, but it is actually an “unsupported setpoint cycle time/data flex layer initialization error,” which falls under the category of parameter-level configuration conflicts. This paper discusses the issue from five dimensions, including drive platform structure and error triggering mechanisms.

I. Background Overview: Why Fault 10.10 is Prone to Misdiagnosis
After replacing an encoder in a servo system, it is necessary to re-establish the electrical angle reference, among other things. Most system errors are directly related to encoder hardware, such as 13.xx indicating encoder loss or feedback channel abnormalities. However, in this case, 10.10 (Setpoint Cycle Time unsupported / Data Flex Layer Init Error) is an alarm related to control cycle synchronization mechanism abnormalities. Due to the fact that encoder replacement is often accompanied by parameter reloading and drive initialization, on-site engineers tend to establish a connection between the encoder and the error, leading to misdiagnosis.

II. SEW MOVIDRIVE® Generation C System Architecture and DFL Explanation
The SEW MOVIDRIVE® adopts a multi-layer data processing system, where motion control and other parameters are distributed and synchronized through the DFL (Data Flex Layer). The DFL is responsible for managing the loading and switching of drive parameter sets, interfacing with bus cycles, validating motion setpoint cycles, and synchronizing feedback data with control loops. When the motion setpoint cycle exceeds limits or does not match the hardware, the drive will prohibit output and trigger Error 10.10 to protect the drive.

III. Why Encoder Replacement Can Indirectly Trigger 10.10
Although encoder replacement is not the direct cause of the 10.10 alarm, it can affect variables such as electrical angle, resolution, protocol, parameter rewriting, and cycle synchronization after engineering reset. This leads the drive to detect that the old operating cycle scheme cannot be adapted to the current hardware configuration, necessitating the resynchronization of system parameters and cycle settings, thereby triggering 10.10.

IV. Technical Troubleshooting Process
Step 1: Confirm Communication Cycle and Drive Support Range
Access the controller/software and check the Communication → Setpoint Cycle Time settings to ensure they are within the recommended range, such as 250us – 2ms for EtherCAT mode. If they exceed the limits, restore them to the supported range.
Step 2: Reinitialize the DFL and Refresh Configuration
Execute Parameter → Data Flex Layer → ReInit, then Save → Reboot Drive.
Step 3: Perform Motor and Feedback Re-matching
Conduct Motor Commission → Encoder Calibration and Rotor Alignment / Commutation Identification.
Step 4: Check for Contradictions in Key Control Parameters
Verify parameters such as Encoder Type, Feedback Resolution, Motor Pole Pairs, and Control Mode to ensure they match. After resetting parameters, execute Save + Reboot.
Step 5: Synchronize Cycles if Involving an Upper-level PLC
Especially in cases of EtherCAT/Profinet/Master Clock, ensure that PLC → Sync Cycle = Inverter Cycle and Clock Drift < 5%.
V. Quick-judgment Experience Rules for Fault 10.10
| Phenomenon | Quick Conclusion |
|---|---|
| Error reported immediately after encoder replacement → but encoder is readable | High probability of cycle/parameter storage not being rebuilt |
| Brief operation after reset, then error recurs after a few seconds | Typical manifestation of setpoint cycle mismatch |
| Returns to normal when original encoder is reinstated | Parameter adaptation issue, not a hardware abnormality |
| Accompanied by output prohibition | Output Stage Inhibit has been triggered |
| 10.10 does not indicate a faulty encoder; it means the drive believes it cannot operate safely with the current cycle. |
VI. Final Conclusions
The occurrence of 10.10 in SEW Generation C MOVIDRIVE drives is not due to encoder hardware failure but rather due to system setpoint cycle or DFL initialization failure.
Encoder replacement is one of the诱因 (contributing factors); the essence lies in parameter mismatch and sampling/cycle conflicts.
Most on-site cases can be resolved by reconfiguring the cycle → reinitializing the DFL → calibrating the encoder and electrical angle.
Class 10 alarms are of the application stop level, with the output stage locked, and must be addressed before continuing operation.
VII. Engineering Recommendations
- When replacing an encoder, zero-point/pole-pair calibration must be performed. Do not misclassify 10.10 as an encoder fault.
- Form a standard inspection unit for system debugging: correct feedback type, matched resolution, control cycle meeting drive hardware requirements, successful DFL initialization, and verification after saving and restarting.
- For high-speed bus servo projects, it is recommended to lock the cycle within the 250 – 500us range.
- It is advisable to back up parameters before release to avoid re-encountering issues during secondary maintenance.