Introduction
The CANWORLD CDE300 series inverter is a high-performance variable frequency drive (VFD) designed for three-phase motor control, widely used in industrial automation. Its primary functions include adjusting motor speed, improving energy efficiency, and ensuring smooth equipment operation. However, in practical applications, inverters may encounter faults due to various reasons. Among these, the ERR10 fault—indicating module overheating—is a common alarm that requires prompt attention to prevent equipment damage or downtime.
This article is based on the “CDE300 CANWORLD Three-Phase User Manual V1.10.pdf” and the provided fault screenshot. It provides an in-depth discussion of the ERR10 fault, including its meaning, potential causes, troubleshooting steps, and preventive measures. Through a clear structure and logical analysis, this article aims to offer practical guidance to help users quickly resolve module overheating issues and ensure long-term stable operation of the equipment.

Meaning of ERR10 Fault
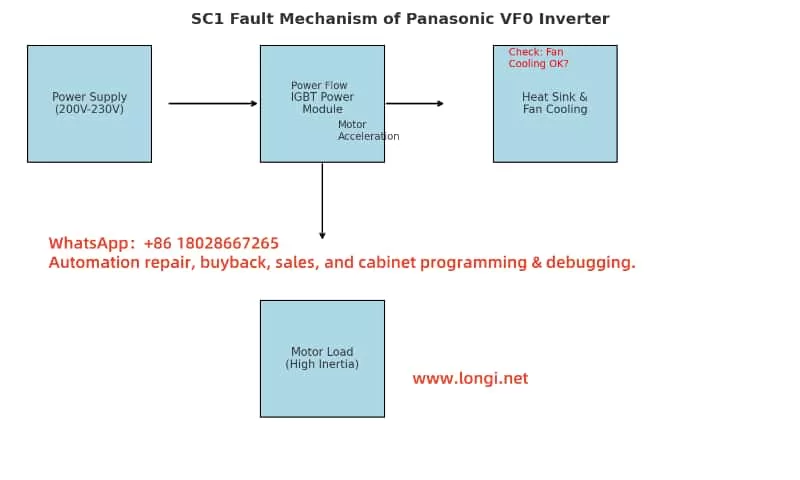
The ERR10 fault in the CANWORLD CDE300 series inverter specifically indicates “module overheating.” The power module of the inverter, typically composed of core components such as Insulated Gate Bipolar Transistors (IGBTs), is responsible for converting the input power into the appropriate output voltage and frequency for motor operation. During operation, these components generate significant heat due to energy losses. To protect the equipment, the inverter is equipped with temperature sensors that monitor the power module’s temperature in real time. When the temperature exceeds a safe threshold, the system triggers the ERR10 fault alarm and may automatically shut down to prevent further thermal damage.
The consequences of module overheating should not be underestimated. Prolonged high temperatures can lead to IGBT aging, performance degradation, and even permanent damage to the power module. Therefore, accurately understanding the ERR10 fault and taking effective measures are crucial.
Possible Causes of ERR10 Fault
Module overheating is usually caused by a combination of factors. Based on the design features of the CDE300 series inverter, the user manual, and common issues in industrial applications, the following are the main potential causes of the ERR10 fault:
- High Ambient Temperature
According to the “Installation Site” section in Chapter 3 (PAGE22) of the user manual, the operating ambient temperature for the CDE300 series inverter should typically be between -10°C and 40°C. If the installation environment exceeds this range, the inverter’s cooling system may be unable to effectively reduce the module temperature, triggering the ERR10 fault. - Poor Ventilation
The inverter requires adequate airflow for heat dissipation. The manual mentions the need for sufficient space around the inverter during installation (PAGE13, Section 2.5.1 “Product Installation Dimensions”). If the installation location is too confined or near other heat sources, heat accumulation may occur, affecting cooling efficiency. - Cooling System Failure or Blockage
The CDE300 series inverter relies on built-in fans and heat sinks for thermal management. If the fan stops working, operates at reduced speed, or if the heat sink is clogged with dust or grease, cooling efficiency will significantly decrease. This is particularly common in industrial environments where the air may contain a high concentration of particulates. - Overloaded Condition
When the load driven by the inverter exceeds its rated capacity, the power module will bear higher current and thermal stress. The manual’s Section 2.3 “CDE300 Series Inverter Models” (PAGE9) lists the rated power for each model, such as CDE300-4T7R5G/011P. If the actual load exceeds the specifications, it may lead to module overheating. - Wiring Issues
Incorrect electrical installation (such as loose or poor connections) can increase resistance, generating additional heat. Section 3.2 “Electrical Installation” (PAGE25) and the “Main Contents of the Distribution Room” on PAGE30 emphasize the importance of proper wiring and grounding. Wiring errors may indirectly cause the ERR10 fault. - High Switching Frequency
A higher switching frequency in IGBTs results in increased heat generation. If the switching frequency is set too high in the inverter’s parameters, it may exacerbate the thermal load on the module, leading to overheating. - Hardware Failure
If all external factors are normal, the issue may lie with the power module or temperature sensor itself, such as a damaged IGBT or a malfunctioning sensor reporting false high temperatures.

Troubleshooting and Solutions for ERR10 Fault
To resolve the ERR10 fault and restore the inverter to normal operation, users can follow these step-by-step troubleshooting procedures:
1. Power Off and Cool Down the Equipment
Upon detecting the ERR10 fault, immediately turn off the inverter’s power and allow the equipment to cool naturally. The “Safety Markings” section in Chapter 1.1 (PAGE4) recommends waiting at least 10 minutes after powering off to ensure internal components have cooled and to avoid safety risks.
2. Check Ambient Temperature
Use a thermometer to measure the temperature around the inverter, ensuring it is within the -10°C to 40°C range. If the temperature is too high, improve environmental conditions by adding ventilation equipment (such as fans or air conditioning) or relocating the inverter.
3. Assess Ventilation and Installation
Refer to Section 2.5 “Product Type Diagram and Installation Hole Dimensions” (PAGE11-13) in the manual to check if there is sufficient space around the inverter (e.g., clearances in front, back, left, and right). Remove any objects that may obstruct airflow and ensure the inverter is not near other heat sources.
4. Clean the Cooling System
Inspect whether the fan is operating normally and clean any dust or debris from the fan blades and heat sink. Use compressed air or a soft brush for cleaning to ensure unobstructed airflow. If the fan is faulty, test its electrical connections and consider replacement.
5. Verify Load Matching
Check if the load parameters match the inverter’s rated capacity (see PAGE9). If the load is too high, reduce the operating load or upgrade to a higher power model. Additionally, inspect the motor for abnormalities (such as short circuits or mechanical jams) that could cause excessive current.
6. Inspect Electrical Connections
Follow the requirements in Section 3.2 “Electrical Installation” (PAGE25) to check the main circuit connections (R, S, T, U, V, W) and grounding (P, P+, P-) for secure and intact connections without looseness or aging. Ensure the input voltage is within the specified range to avoid overcurrent.
7. Adjust Switching Frequency
Using the keypad operation (Chapter 4, PAGE37), access the parameter settings interface to check and reduce the switching frequency (if the application allows). This can decrease the heat generated by the IGBTs, but be cautious not to affect motor performance.
8. Monitor Operation and Test
After completing the above adjustments, restart the inverter and observe its operating status. If the equipment provides temperature display functionality, monitor the module temperature in real time. If the ERR10 fault persists, it may indicate a hardware issue, and it is recommended to contact CANWORLD technical support for further inspection.
Preventive Measures for ERR10 Fault
To prevent the recurrence of the ERR10 fault, users can implement the following preventive measures:
- Regular Maintenance
Conduct a comprehensive inspection of the inverter every 3-6 months, cleaning the fan and heat sink to ensure the cooling system functions properly. In industrial environments, maintenance intervals may need to be shortened. - Optimize Installation Environment
Choose a well-ventilated installation location away from heat sources, avoiding direct sunlight or high-temperature areas, in accordance with Section 3.1 of the manual. - Proper Load Management
Monitor load conditions in real time to avoid prolonged overload operation. Utilize the inverter’s built-in diagnostic functions or external devices to track current and temperature. - Parameter Optimization
Adjust operating parameters based on actual application needs, such as switching frequency and acceleration/deceleration times, to minimize unnecessary heat generation. - Personnel Training
Train operators to familiarize them with the safety and installation guidelines in the manual and to equip them with basic troubleshooting skills. - Enhanced Cooling Measures
In high-temperature environments, install additional external fans or air conditioning to further improve heat dissipation.
Conclusion
The ERR10 fault (module overheating) in the CANWORLD CDE300 series inverter is a critical protective alarm that may be triggered by high ambient temperatures, poor ventilation, cooling system failures, overloaded conditions, wiring issues, or hardware malfunctions. Through systematic troubleshooting—from checking the environment to adjusting parameters and performing maintenance—users can typically identify and resolve the issue quickly. Additionally, by implementing regular maintenance and optimizing the operating environment, the likelihood of ERR10 faults can be significantly reduced.
The CDE300 series inverter is renowned for its reliability, but its performance depends on proper installation and maintenance. By following the guidelines in the user manual and the solutions and preventive suggestions provided in this article, users can not only address current module overheating issues but also enhance the overall lifespan and efficiency of the equipment, ensuring stability and safety in industrial applications. For complex issues, it is advisable to contact CANWORLD’s official technical support for professional assistance.