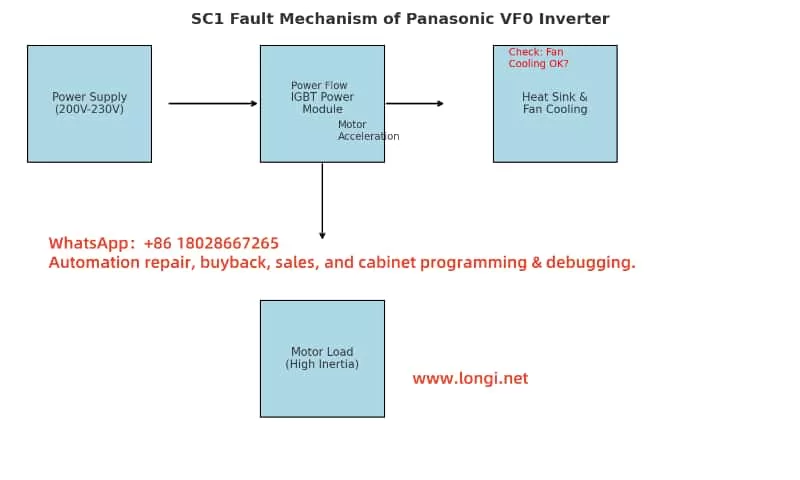
Introduction
The Saice SES800III servo drive is a high-performance device widely used in industrial automation, delivering precise control in various applications. Despite its reliability, users may encounter fault codes during prolonged operation or under challenging conditions, with the A.83 fault code being a notable issue. This code specifically indicates a resolver signal failure, pointing to an anomaly in the feedback signal from the resolver, a critical sensor for monitoring motor rotor position. A resolver failure can compromise motor control accuracy and potentially halt system operations, causing significant production disruptions.
This article provides a comprehensive analysis of the A.83 fault, including its causes, detailed troubleshooting steps, and preventive measures. The goal is to equip users with practical, systematic guidance to resolve the issue efficiently and ensure long-term equipment stability.

Definition of the A.83 Fault
In the Saice SES800III servo drive, the A.83 fault code is designated to indicate a resolver signal failure. A resolver is a robust electromagnetic sensor mounted within the motor, designed to detect the rotor’s angular position and transmit this data to the drive for precise speed and position control. Compared to optical encoders, resolvers are preferred in industrial settings due to their resilience to high temperatures, vibrations, and contaminants.
When the resolver signal is interrupted, distorted, or otherwise abnormal, the drive detects the issue and triggers the A.83 fault code. This typically prompts the system to enter a protective mode, stopping the motor and displaying an alarm on the control panel or monitoring software.
Possible Causes of the A.83 Fault
The A.83 fault is typically linked to the resolver or its signal transmission path. Below are the common causes, spanning hardware, environmental, and installation factors:
1. Wiring Issues
- Poor Contact: Loose connections between the resolver and drive due to prolonged vibration or improper installation can destabilize signal transmission.
- Wiring Errors: Incorrect connections of signal lines (e.g., SIN, COS, EXC) to the wrong terminals during initial setup or maintenance can disrupt normal operation.
2. Damaged Signal Cables
- Physical Damage: Cables may break, short-circuit, or lose insulation due to mechanical friction, compression, or external impacts.
- Aging: In high-temperature, humid, or corrosive environments, cable insulation may degrade, reducing signal quality over time.
3. Resolver Failure
- Internal Damage: Defects in the resolver’s coils, magnetic core, or other components, whether from manufacturing or wear, can lead to signal loss.
- Misalignment: Improper alignment between the resolver and motor shaft can result in distorted position signals.
4. Environmental Factors
- Temperature Extremes: Operating beyond the recommended temperature range (typically 0-40°C) can impair resolver performance.
- Vibration Interference: Excessive mechanical vibration may loosen internal components or connections within the resolver.
- Humidity Effects: High humidity (>90% RH) can cause short circuits or signal interference in electrical components.
5. Electromagnetic Interference (EMI)
- Poor Grounding: Inadequate grounding of the drive or resolver can expose signals to external electromagnetic noise.
- External Sources: Nearby high-power devices (e.g., inverters, motors, or radio equipment) may generate electromagnetic radiation that interferes with resolver signals.
Troubleshooting Steps
To quickly identify and resolve the A.83 fault, users should follow these systematic troubleshooting steps:
1. Inspect Wiring Integrity
- Visual Check: Examine all connections between the resolver and drive, ensuring plugs are secure and free of looseness or detachment.
- Electrical Testing: Use a multimeter to test the continuity of signal lines (SIN, COS, EXC) for open circuits or shorts.
- Terminal Verification: Cross-check all connections against the equipment manual to rule out wiring errors.
2. Assess Signal Cable Condition
- Visual Inspection: Look for signs of wear, breaks, or excessive bending in the signal cables, replacing damaged sections as needed.
- Cable Routing: Ensure signal lines are routed away from power cables or interference sources, preferably using shielded cables.
3. Test Resolver Performance
- Signal Analysis: Use an oscilloscope to check the SIN and COS signal waveforms, verifying amplitude, phase, and frequency against standards.
- Replacement Test: Swap the suspected faulty resolver with a known good unit to determine if the issue lies with the resolver itself.
- Alignment Adjustment: Check the resolver’s alignment with the motor shaft; recalibrate if misalignment is detected.
4. Improve Operating Environment
- Temperature Control: Maintain the environment within the recommended temperature range, adding ventilation or cooling if necessary.
- Vibration Reduction: Install vibration dampers on the equipment base or adjust the layout to minimize vibration.
- Humidity Management: Use dehumidifiers in high-humidity settings to protect electrical components.
5. Mitigate Electromagnetic Interference
- Grounding Optimization: Verify that the drive and resolver are properly grounded, with resistance meeting specifications.
- Shielding: Add shielding to signal lines or use ferrite cores to suppress high-frequency interference.
6. Reset and Test the System
- Fault Clearance: After repairs, reset the drive according to the manual (e.g., press the RST key) to clear the fault code.
- Operational Verification: Run the motor in low-speed mode (e.g., set parameter Pr0.26=0) to confirm normal operation.
7. Seek Professional Support
- If the issue persists after the above steps, it may indicate a complex internal fault in the drive or resolver. Contact Saice technical support or an authorized service center for advanced diagnosis.

Preventive Measures
To prevent the A.83 fault and enhance equipment reliability, consider the following proactive steps:
- Regular Inspections: Conduct comprehensive checks of wiring, signal cables, and the resolver every 3-6 months to catch potential issues early.
- Environmental Optimization: Keep the operating environment clean, dry, and at a stable temperature to avoid extreme conditions affecting the equipment.
- Proper Installation: Adhere strictly to manual guidelines during installation and commissioning to ensure correct configuration of the resolver and drive.
- Staff Training: Train operators and maintenance personnel on troubleshooting procedures and equipment care to improve response capabilities.
Conclusion
The A.83 fault (resolver signal failure) in the Saice SES800III servo drive is a critical issue requiring prompt attention. This guide offers a thorough breakdown of its causes, troubleshooting methods, and preventive strategies, enabling users to address the problem effectively and minimize downtime. Whether the fault stems from wiring issues, cable damage, or environmental factors, a systematic approach can resolve most cases. For complex scenarios, professional assistance from Saice is recommended. This resource aims to support users in maintaining stable, efficient operations over the long term.