I. Instrument Principle and Features
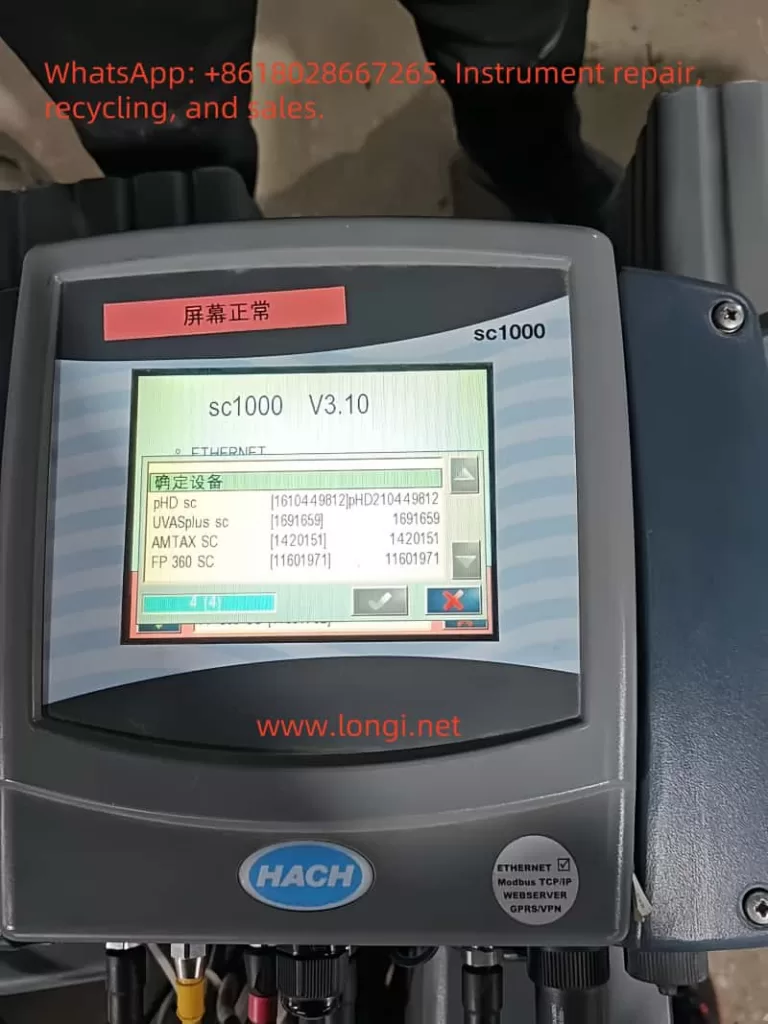
The Hach Amtax SC Ammonia Nitrogen Analyzer is an online analytical device specifically designed for continuous monitoring of ammonium ion concentration in water bodies. It is widely used in wastewater treatment plants, waterworks, surface water monitoring, and industrial process control. Its core measurement principle is the Gas Sensitive Electrode (GSE) method, where a selective electrode reacts with ammonium ions in the sample, and the concentration value is ultimately output in the form of NH₄–N on the controller (sc1000).
Key Technical Features:
- Wide Measurement Range: Covers three intervals: 0.05–20 mg/L, 1–100 mg/L, and 10–1000 mg/L, allowing flexible application in both low-concentration surface water and high-concentration wastewater scenarios.
- Fast Response: 90% response time of less than 5 minutes, suitable for real-time monitoring of dynamic water quality.
- High Precision and Reproducibility: Measurement error is less than ±3% or ±0.05 mg/L (for low ranges), ensuring reliable data.
- Automation Capabilities: Features automatic calibration, automatic cleaning, and diagnostic functions, significantly reducing manual intervention.
- Robust Design: Enclosure with an IP55 protection rating and made of UV-resistant ASA/PC material, suitable for harsh outdoor environments.
- Modular Expandability: Enables data transmission and remote monitoring through the sc1000 controller, supporting single-channel or dual-channel modes.
Thus, the Amtax SC combines high precision, low maintenance, and strong adaptability, making it a mainstream choice in the field of ammonia nitrogen online monitoring.
II. Installation and Calibration
1. Mechanical Installation
- Mounting Options: Supports wall mounting, rail mounting, or vertical installation, with wall mounting being the most common. Choose a sturdy, load-bearing wall and ensure smooth routing of surrounding pipes and cables.
- Weight and Load Requirements: The instrument weighs approximately 31 kg, and the bracket must support a load of ≥160 kg.
- Installation Environment: Avoid strong vibrations, strong magnetic fields, and direct sunlight. Maintain an ambient temperature range of –20 to 45°C.
2. Electrical Installation
- Must be performed by qualified personnel to ensure proper grounding and the installation of a residual current device (30 mA RCD).
- Power is supplied by the sc1000 controller, with voltages of 115V or 230V. The use of 24V controller models is prohibited.
- All piping and reagent installations must be completed before powering on.
3. Reagent and Electrode Installation
- Reagent Preparation: Select standard solutions and reagents according to the measurement range. For example, use 1 mg/L and 10 mg/L standard solutions for low ranges, and 50 mg/L and 500 mg/L for high ranges.
- Electrode Installation: Fill with electrolyte (approximately 11 mL), ensuring no air bubbles remain, and correctly insert the electrode into the electrolysis cell. Replace the membrane cap and electrolyte every 2–3 months.
- Humidity Sensor: Must be correctly wired to prevent alarms triggered by condensation or liquid leakage.
4. Calibration Procedure
- Calibration modes include automatic calibration and manually triggered calibration.
- Set the calibration interval (typically once per day or shorter), and the system will automatically switch standard solutions for electrode correction.
- After calibration, the system records key parameters such as slope, zero point, and standard solution potential to ensure long-term stable operation.

III. Startup and Operation
1. Startup Steps
- Ensure all installations (piping, electrical, reagents, electrodes) are complete.
- Connect the analyzer to the sc1000 controller and power on.
- Initialize the system: Register the Amtax SC and sampling probe in the controller, execute the “Prepump All” function to fill the piping.
- Allow a warm-up time of approximately 1 hour for the instrument, reagents, and electrodes to reach operating temperature.
- Enter the sensor setup menu to confirm the measurement range, output units (mg/L or ppm), and measurement interval.
2. Normal Operation
- LED Indicators: Green indicates normal operation, orange indicates a warning, and red indicates an error.
- Measurement Interval: Adjustable from 5 to 120 minutes, depending on application requirements.
- Data Viewing: The sc1000 controller displays real-time values, historical trends, and alarm status, and can upload data to a monitoring system via a bus interface.
- Cleaning Function: Set up timed automatic cleaning to ensure the photometer, piping, and electrodes remain clean.
IV. Troubleshooting and Maintenance
1. Routine Maintenance
- Appearance Inspection: Regularly check for damage to pipes and cables, and confirm the absence of leaks or corrosion.
- Fan Filter: Clean or replace every 6–12 months to ensure proper heat dissipation.
- Reagents and Electrodes: Replace reagents every 2–3 months, electrode membrane caps and electrolyte every 2–3 months, and electrodes every 1–2 years, as recommended in Table 5.
- Cleaning Cycle: Depends on water hardness; typically perform automatic cleaning every 1–8 hours.
2. Common Faults and Solutions
- Low/High Temperature: If the internal temperature falls below 4°C or rises above 57°C, the system enters service mode. Check the heating or cooling fan.
- Humidity Alarm: Liquid detected in the collection tray; locate and repair the leak source.
- Abnormal Electrode Slope: Check the membrane and electrolyte, replace the standard solution; if the issue persists, replace the electrode.
- Weak Photometer Signal: Trigger cleaning; if unresolved, manually clean or contact a service technician.
3. Long-Term Shutdown and Storage
- Flush the instrument with distilled water in a circulation mode to empty the pipes and reagent bottles.
- Remove the electrode, clean it, and reinstall it in the electrolysis cell, keeping it moist during storage.
- Install transport locks and store in a dry, frost-free environment.
4. Professional Repairs
- Certain components (such as pumps, compressors, and main circuit boards) must be replaced by the manufacturer or authorized service personnel. Typical service lives: pumps 1–2 years, compressors 2 years, all covered under warranty.
V. Conclusion
The Hach Amtax SC Ammonia Nitrogen Analyzer is a stable and highly automated online monitoring device. It features a scientific principle, clear installation requirements, a straightforward operation process, and comprehensive maintenance methods. By strictly adhering to the user manual and this guide, users can ensure the long-term stable operation of the device, providing reliable data support for water quality monitoring and wastewater treatment process control. Correct installation, regular calibration, and maintenance are key to ensuring the instrument’s long-term stable operation. Users should strictly follow the safety specifications in the operation manual, regularly replace reagents and electrodes, and promptly address fault alarms to ensure measurement accuracy and extend the instrument’s service life.